Deploying Buildbot on Kubernetes
Mon 12 December 2016
Mon 12 December 2016
TLDR: If you just want to see the end-result of this post, the results can be found at this GitHub Repository: https://github.com/ElijahCaine/buildbot-on-kubernetes
I'm learning Kubernetes (K8s) for work and decided to try my hand at deploying Buildbot with K8s because we all know the universal law discovered made by Science McSmartyPants in the 1758 which stated: doing cool shit > reading docs [docs-should]. I would describe K8s and Buildbot, but they each already did that:
"Buildbot is an open-source framework for automating software build, test, and release processes."
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
If that still didn't make sense, don't worry you should keep reading. This is a fun post.
NOTE: As you read this post keep in mind: it might walk like a tutorial, quack like a tutorial, and even read like a tutorial, but I promise you that it is in fact not a tutorial.
This post is an adventure.
Here's a quick rundown of what I want to achieve:
I have never deployed Buildbot ever for anything. I have also not really worked with K8s until starting my recent jorb at CoreOS. Why Buildbot and why K8s?
Anyway, let's get started.
I'm using the latest version of K8s and Minikube, which is backed by Virtualbox on a 2014 MacBook Pro running OSX.
Minikube version and associated OS:
$ minikube version minikube version: v0.13.1 $ minikube ssh ... Boot2Docker version 1.11.1, build master : 901340f - Fri Jul 1 22:52:19 UTC 2016 Docker version 1.11.1, build 5604cbe docker@minikube:~$
There's some Minikube-specific semantics in this post, but you can probably get by with whatever K8s back-end you want/have lying around.
Kubernetes version:
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"4", GitVersion:"v1.4.6", GitCommit:"e569a27d02001e343cb68086bc06d47804f62af6", GitTreeState:"clean", BuildDate:"2016-11-12T05:22:15Z", GoVersion:"go1.7.1", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"4", GitVersion:"v1.4.6", GitCommit:"e569a27d02001e343cb68086bc06d47804f62af6", GitTreeState:"clean", BuildDate:"1970-01-01T00:00:00Z", GoVersion:"go1.7.1", Compiler:"gc", Platform:"linux/amd64"}
Between finishing editing and pushing this post the above versions will probably be out of date. SHRUG. What are you gonna do. Software, amirite?
Virtualbox version:
$ virtualbox --help Oracle VM VirtualBox Manager 5.1.6 ...
OSX Version and hardware:
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.10.5
BuildVersion: 14F1912
$ system_profiler
...
Hardware Overview:
Model Name: MacBook Pro
Model Identifier: MacBookPro11,1
Processor Name: Intel Core i5
Processor Speed: 2.6 GHz
Number of Processors: 1
Total Number of Cores: 2
...
Memory: 16 GB
...
...
The hardware and Virtualbox versions are a little less important, but might as well be included for completeness.
The Buildbot project is nice enough to provide some Buidlbot Docker infrastructure to start working with. It uses a Docker Compose YAML file to deploy one worker container, one master service, and one PostgreSQL service, each of which is linked together and just works™
Great! In theory [theory-vs-practice] we can just translate the options in docker-compose.yml to K8s options to get a simple cluster up and running. Which, to clarify, isn't an established thing, it's just a process I'm guessing should work based on the fact that Docker Compose and K8s are both orchestration tools. One is way more complicated and robust, but At least some of their features should over-lap in that Venn diagram.
Once we've got a nieve translated-docker-compose k8s setup running then we can (hopefully) tweak some knobs and get persistent storage and auto-scaling working [why].
Let's start really basic and just try to get something running with kubectl run. We'll use K8s to deploy a Buildbot master container mentioned in that docker-compose.yml with translated configuration options from that file. Remember, we're just mapping a docker-compose.yml into a K8s setup to begin. Nothing fancy, no pre-emptive optimizations, just this:
$ kubectl run master \
--image=buildbot/buildbot-master:master \
--env="BUILDBOT_CONFIG_DIR=config" \
--env="BUILDBOT_CONFIG_URL=https://github.com/buildbot/buildbot-docker-example-config/archive/master.tar.gz" \
--env="BUILDBOT_WORKER_PORT=9989" \
--env="BUILDBOT_WEB_URL=http://localhost:8080/" \
--env="BUILDBOT_WEB_PORT=8080" \
--port=8080
Some reading later and I can tell you that command started a Deployment of Pods. To see if it worked, let's run kubect get pods.
$ kubectl get pods NAME READY STATUS RESTARTS AGE master-4259088255-afsfk 1/1 Running 1 10s
This looks pretty good...
$ kubectl get pods NAME READY STATUS RESTARTS AGE master-4259088255-afsfk 0/1 CrashLoopBackOff 2 1m
... nooo! The thing was at 1/1 and now it's at 0/1 and it says CrashLoopBackOff. Numbers going down when they're supposed to stay the same is never a good sign, and crashing is almost never what you want.
If I've learned anything about fixing stuff that's broke it's always check the logs.
$ kubectl logs po/master-4259088255-afsfk [...] 2016-12-09 22:31:42+0000 [-] Setting up database with URL 'sqlite:' 2016-12-09 22:31:42+0000 [-] The Buildmaster database needs to be upgraded before this version of [...] 2016-12-09 22:31:42+0000 [-] BuildMaster startup failed 2016-12-09 22:31:42+0000 [-] BuildMaster is stopped 2016-12-09 22:31:42+0000 [-] Main loop terminated. 2016-12-09 22:31:42+0000 [-] Server Shut Down.
Gross, but probably useful. How? Good question:
Just like with the master container, we're just going to use CLI arguments to get a database running.
$ kubectl run postgres \
--image=postgres:9.4\
--env="POSTGRES_PASSWORD=change_me" \
--env="POSTGRES_USER=buildbot" \
--env="POSTGRES_DB=buildbot" \
--env="BUILDBOT_DB_URL=postgresql+psycopg2://{POSTGRES_USER}:{POSTGRES_PASSWORD}@db/{POSTGRES_DB}"\
--port=5432
Cross fingers aaand...
$ kubectl get pods NAME READY STATUS RESTARTS AGE master-4259088255-afsfk 0/1 CrashLoopBackOff 6 9m postgres-2443857112-3ermh 0/1 ContainerCreating 0 15s
/me holds breath
$ kubectl get pods NAME READY STATUS RESTARTS AGE master-4259088255-afsfk 0/1 CrashLoopBackOff 6 9m postgres-2443857112-3ermh 1/1 Running 0 54s
Yuss! Wait, for real?
$ kubectl logs postgres-2443857112-3ermh [... hey look a bunch of useful Postgres garbage ...] PostgreSQL init process complete; ready for start up. [... some more useful Postgres garbage ...]
Good 'nuff. Now how does this database plug into the master container?
Well, in the Docker Compose world, containers talked to one-another on a private network with the link directive. There's probably some way to do we do that with K8s right?
Running Command-Line Interface (CLI) commands is fun, but the easiest way to get this system running seems to be with configuration files. I'm sure I can use CLI commands to orchestrate this entire project, but... honestly all the tutorials talk about how to do things in YAML so we're doing it in YAML now.
Some research later it looks like declaring a Pod is the way to go? For context, here's where I got the idea from the K8s docs:
A pod (as in a pod of whales or pea pod) is a group of one or more containers (such as Docker containers), the shared storage for those containers, and options about how to run the containers.
Well that sounds roughly like what we're doing. I've got some containers, I want them to be able to talk to each other, and they're all logically connected to one another. Let's go down this rabbit hole.

Here I have Frankensteined this config buildbot.yaml from examples in the configs:
apiVersion: 'v1' kind: 'Pod' metadata: name: 'buildbot' labels: app: 'buildbot' spec: containers: - name: 'master' image: 'buildbot/buildbot-master:master' ports: - containerPort: 8080 env: - name: 'BUILDBOT_CONFIG_DIR' value: 'config' - name: 'BUILDBOT_CONFIG_URL' value: 'https://github.com/buildbot/buildbot-docker-example-config/archive/master.tar.gz' - name: 'BUILDBOT_WORKER_PORT' value: '9989' - name: 'BUILDBOT_WEB_URL' value: 'http://localhost:8080/' - name: 'BUILDBOT_WEB_PORT' value: '8080' - name: 'POSTGRES_PASSWORD' value: 'change_me' - name: 'POSTGRES_USER' value: 'buildbot' - name: 'POSTGRES_DB' value: 'buildbot' - name: 'BUILDBOT_DB_URL' value: 'postgresql+psycopg2://{POSTGRES_USER}:{POSTGRES_PASSWORD}@db/{POSTGRES_DB}' - name: 'postgres' image: 'postgres:9.4' ports: - containerPort: 5432 env: - name: 'POSTGRES_PASSWORD' value: 'change_me' - name: 'POSTGRES_USER' value: 'buildbot' - name: 'POSTGRES_DB' value: 'buildbot' - name: 'BUILDBOT_DB_URL' value: 'postgresql+psycopg2://{POSTGRES_USER}:{POSTGRES_PASSWORD}@db/{POSTGRES_DB}'
What happens when we run it?
Well first we need to clean up that CLI-created garbage we were doing earlier.
$ kubectl delete deployment master postgres deployment "master" deleted deployment "postgres" deleted
Then deploy the new pod:
$ kubectl create -f buildbot.yaml pod "buildbot" created
Aaaand:
$ kubectl get pods buildbot 2/2 Running 0 23s
I'm suspicious...
$ kubectl logs po/buildbot master checking basedir /usr/lib/python2.7/site-packages/buildbot/config.py:85: ConfigWarning: [0.9.0 and later] `buildbotNetUsageData` is not configured and defaults to basic [...] Failure: sqlalchemy.exc.OperationalError: (psycopg2.OperationalError) could not translate host name "db" to address: Try again [...] problem while upgrading!: Traceback (most recent call last): [... python traceback ...] OperationalError: (psycopg2.OperationalError) could not translate host name "db" to address: Try again
Whelp let's play 'Where do I fix that?'
If you guessed c you would be right so let's start in buildbot.yaml.
Based on my experience with databases, specifically the startup time of database containers like Postgres and MariaDB, I'd guess that the database was taking too long to start. After some digging around, I found out that Pods were the entirely wrong way to go. Here's how that discovery went:
So let's run that example to make sure it all works fine.
$ kubectl create -f local-volumes.yaml persistentvolume "local-pv-1" created persistentvolume "local-pv-2" created $ kubectl create -f mysql-deployment.yaml service "wordpress-mysql" created persistentvolumeclaim "mysql-pv-claim" created deployment "wordpress-mysql" created $ kubectl create -f wordpress-deployment.yaml service "wordpress" created persistentvolumeclaim "wp-pv-claim" created deployment "wordpress" created $ kubectl get all NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/kubernetes 10.0.0.1 <none> 443/TCP 2h svc/wordpress 10.0.0.28 <pending> 80/TCP 5s svc/wordpress-mysql None <none> 3306/TCP 17s NAME READY STATUS RESTARTS AGE po/buildbot 2/2 Running 0 8m po/wordpress-1618093523-4if9k 0/1 ContainerCreating 0 5s po/wordpress-mysql-2379610080-mqvll 0/1 ContainerCreating 0 17s NAME STATUS VOLUME CAPACITY ACCESSMODES AGE pvc/mysql-pv-claim Bound local-pv-1 20Gi RWO 17s pvc/wp-pv-claim Bound local-pv-2 20Gi RWO 5s
And I can go to the site?
Great.
Now we need to morph wordpress-deployment.yaml into postgres.yaml, and wordpress-deployment.yaml into master.yaml Also, let's ignore local-volumes.yaml for now, just to be safe. Don't forget: we're not doing anything fancy yet.
master.yaml:
apiVersion: v1 kind: Service metadata: name: master labels: app: buildbot spec: ports: - port: 8080 name: frontend selector: app: buildbot tier: master type: NodePort --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: master labels: app: buildbot spec: strategy: type: Recreate template: metadata: labels: app: buildbot tier: master spec: containers: - name: master image: buildbot/buildbot-master:master env: - name: BUILDBOT_CONFIG_DIR value: config - name: BUILDBOT_CONFIG_URL value: 'https://raw.githubusercontent.com/buildbot/buildbot-docker-example-config/master/master.cfg' - name: BUILDBOT_WORKER_PORT value: '9989' - name: BUILDBOT_WEB_URL value: 'http://localhost:8080/' - name: BUILDBOT_WEB_PORT value: '8080' - name: POSTGRES_PASSWORD value: change_me - name: POSTGRES_USER value: buildbot - name: POSTGRES_DB value: buildbot - name: POSTGRES_DB_HOST value: postgres - name: BUILDBOT_DB_URL value: 'postgresql+psycopg2://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_DB_HOST}/{POSTGRES_DB}' ports: - containerPort: 8080 name: frontend
postgres.yaml:
apiVersion: v1 kind: Service metadata: name: postgres labels: app: buildbot spec: ports: - port: 5432 name: postgres selector: app: buildbot tier: postgres clusterIP: None --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: postgres labels: app: buildbot spec: strategy: type: Recreate template: metadata: labels: app: buildbot tier: postgres spec: containers: - image: postgres:9.4 name: postgres env: - name: POSTGRES_PASSWORD value: change_me - name: POSTGRES_USER value: buildbot - name: POSTGRES_DB value: buildbot - name: POSTGRES_DB_HOST value: postgres - name: BUILDBOT_DB_URL value: 'postgresql+psycopg2://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_DB_HOST}/{POSTGRES_DB}' ports: - containerPort: 5432 name: postgres
And with a flick of my wand:
$ kubectl delete pods,deployment,service --all # cleanup the old stuff pod "buildbot" deleted pod "wordpress-1618093523-4if9k" deleted pod "wordpress-mysql-2379610080-mqvll" deleted deployment "wordpress" deleted deployment "wordpress-mysql" deleted service "kubernetes" deleted service "wordpress" deleted service "wordpress-mysql" deleted $ kubectl create -f postrges.yml service "postgres" created deployment "postgres" created $ kubectl create -f master.yml service "master" created deployment "master" created $ minikube service master
Opens up this wonderful site:
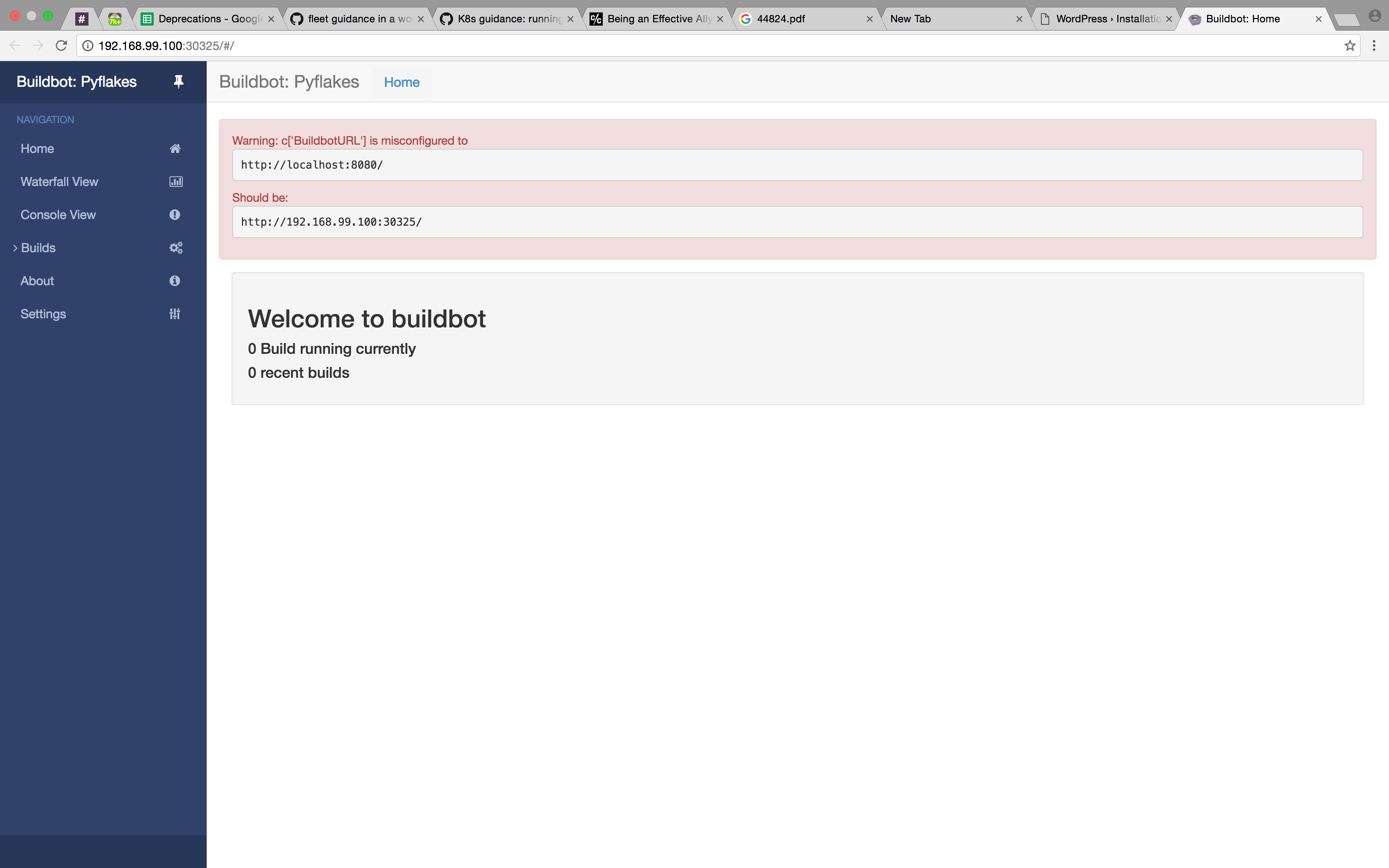
Great, they can talk [same-app-note].
So we've got a website and a database, but we're not actually running any builds yet. Let's fix that.
Based on what the docker-compose.yml says we should be able to throw this together and have it work:
worker.yaml:
apiVersion: v1 kind: Service metadata: name: worker labels: app: buildbot spec: ports: - port: 9989 name: worker selector: app: buildbot tier: worker clusterIP: None --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: worker labels: app: buildbot spec: strategy: type: Recreate template: metadata: labels: app: buildbot tier: worker spec: containers: - image: "buildbot/buildbot-worker:master" name: worker env: - name: BUILDMASTER value: master - name: BUILDMASTER_PORT value: '9989' - name: WORKERNAME value: example-worker - name: WORKERPASS value: pass - name: WORKER_ENVIRONMENT_BLACKLIST value: 'DOCKER_BUILDBOT* BUILDBOT_ENV_* BUILDBOT_1* WORKER_ENVIRONMENT_BLACKLIST' ports: - containerPort: 9989 name: worker
$ kubectl create -f worker.yaml service "worker" created deployment "worker" created $ kubectl get -f worker.yaml NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/worker None <none> 9989/TCP 44s NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/worker 1 1 1 0 44s
Looks promising...
$ kubectl get pods -l tier=worker
NAME READY STATUS RESTARTS AGE
worker-3607067131-qdpfd 1/1 Running 0 1m
$ kubectl logs worker-3607067131-ke4zb -f
2016-11-21 19:46:45+0000 [-] Loading buildbot.tac...
2016-11-21 19:46:45+0000 [-] Loaded.
2016-11-21 19:46:45+0000 [-] twistd 16.5.0 (/usr/bin/python 2.7.12) starting up.
2016-11-21 19:46:45+0000 [-] reactor class: twisted.internet.epollreactor.EPollReactor. 2016-11-21 19:46:45+0000 [-] Starting Worker -- version: latest
2016-11-21 19:46:45+0000 [-] recording hostname in twistd.hostname
2016-11-21 19:46:45+0000 [-] Starting factory <buildbot_worker.pb.BotFactory instance at 0x7fd8c2339cf8>
2016-11-21 19:46:45+0000 [-] Connecting to buildbot:9989
2016-11-21 19:46:56+0000 [Uninitialized] Connection to buildbot:9989 failed: Connection Refused
2016-11-21 19:46:56+0000 [Uninitialized] <twisted.internet.tcp.Connector instance at 0x7fd8c233a170> will retry in 2 seconds
2016-11-21 19:46:56+0000 [-] Stopping factory <buildbot_worker.pb.BotFactory instance at 0x7fd8c2339cf8>
2016-11-21 19:46:59+0000 [-] Starting factory <buildbot_worker.pb.BotFactory instance at 0x7fd8c2339cf8>
2016-11-21 19:46:59+0000 [-] Connecting to buildbot:9989
2016-11-21 19:47:29+0000 [-] Connection to buildbot:9989 failed: [Failure instance: Traceback (failure with no frames): <class 'twisted.internet.error.TimeoutError'>: User timeout caused connection failure.
]
2016-11-21 19:47:29+0000 [-] <twisted.internet.tcp.Connector instance at 0x7fd8c233a170> will retry in 5 seconds
2016-11-21 19:47:29+0000 [-] Stopping factory <buildbot_worker.pb.BotFactory instance at 0x7fd8c2339cf8>
Khaaaaaan!
Fine, let's get to work debugging. First we'll login to the worker pod and try to ping the buildbot pod since the output makes it seem like there was a timeout between the host and the worker. This usually means they can't reach each other.
$ kubectl exec -it worker-3607067131-qdpfd bash buildbot@worker-3607067131-qdpfd:/buildbot$ ping master bash: ping: command not found
Uhh...
buildbot@worker-3607067131-ke4zb:/buildbot$ curl http://master:8080 <!DOCTYPE html>[... definitely actually a webpage ...]
So the worker can reach the master, but can the master reach the worker?
$ kubectl get pods -l tier=master NAME READY STATUS RESTARTS AGE master-2152810066-9ip8b 1/1 Running 0 21m $ kubectl exec -it master-2152810066-9ip8b sh /var/lib/buildbot # ping worker PING worker (172.17.0.6): 56 data bytes 64 bytes from 172.17.0.6: seq=0 ttl=64 time=0.083 ms 64 bytes from 172.17.0.6: seq=1 ttl=64 time=0.101 ms ^C --- worker ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.083/0.092/0.101 ms
Okay, so they can connect to one-another. What's the problem then? My best guess is that the master pod needs to have it's special worker port (9989) exposed. So let's add those lines to master.yaml:
--- a/blogpost/updated-master.yaml +++ b/blogpost/updated-master.yaml @@ -8,6 +8,8 @@ spec: ports: - port: 8080 name: frontend + - port: 9989 + name: worker selector: app: buildbot tier: master @@ -55,3 +57,5 @@ spec: ports: - containerPort: 8080 name: frontend + - containerPort: 9989 + name: worker
And after tearing everything down and bringing it back up:
$ kubectl get pods -l tier=worker NAME READY STATUS RESTARTS AGE worker-2552724660-l4kmv 1/1 Running 0 12s $ kubectl logs worker-2552724660-l4kmv [... logs logs logs ...] 2016-12-09 23:30:18+0000 [-] Connecting to master:9989 2016-12-09 23:30:18+0000 [HangCheckProtocol,client] message from master: attached 2016-12-09 23:30:18+0000 [HangCheckProtocol,client] message from master: attached 2016-12-09 23:30:18+0000 [HangCheckProtocol,client] Connected to master:9989; worker is ready 2016-12-09 23:30:18+0000 [HangCheckProtocol,client] sending application-level keepalives every 600 seconds
Hey that looks like success to me! How does the front-end look?
$ kubectl get pods -l tier=master NAME READY STATUS RESTARTS AGE master-3038604518-jim6q 1/1 Running 0 2m $ kubectl port-forward master-3038604518-jim6q 8080
And in a browser:
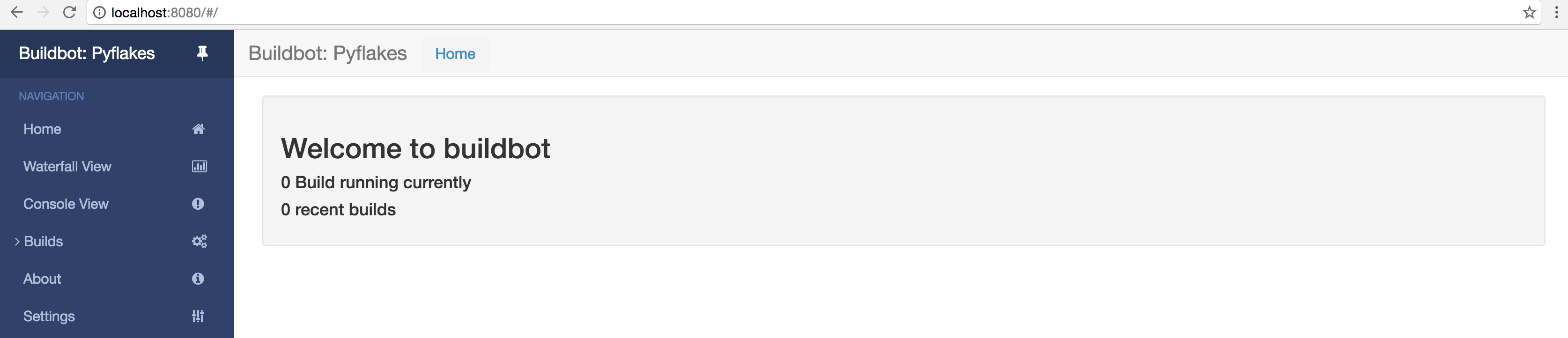
You may now do a happy dance.

We've got the three core moving parts of our system, next on our list is adding some persistent storage. Thankfully, we can recycle the MySQL+Wordpress example we used before. Yay examples.
So let's add the storage bits back in that we ignored before. This results in configs that look like so (abbreviated for your scrollbar's convenience):
volumes.yaml:
apiVersion: v1 kind: PersistentVolume metadata: name: local-pv-1 labels: type: local spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /data/pv-1 --- apiVersion: v1 kind: PersistentVolume metadata: name: local-pv-2 labels: type: local spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /data/pv-2 --- apiVersion: v1 kind: PersistentVolume metadata: name: local-pv-3 labels: type: local spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /data/pv-3
master.yaml:
diff --git a/blogpost/volumes-master.yaml b/blogpost/volumes-master.yaml index 7cbffd7..c7479e3 100644 --- a/blogpost/volumes-master.yaml +++ b/blogpost/volumes-master.yaml @@ -15,6 +15,19 @@ spec: tier: master type: NodePort --- +apiVersion: v1 +kind: PersistentVolumeClaim +metadata: + name: master-pv-claim + labels: + app: buildbot +spec: + accessModes: + - ReadWriteOnce + resources: + requests: + storage: 1Gi +--- apiVersion: extensions/v1beta1 kind: Deployment metadata: @@ -37,7 +50,7 @@ spec: - name: BUILDBOT_CONFIG_DIR value: config - name: BUILDBOT_CONFIG_URL - value: 'https://raw.githubusercontent.com/buildbot/buildbot-docker-example-config/master/master.cfg' + value: 'https://raw.githubusercontent.com/ElijahCaine/buildbot-on-kubernetes/master/simple/master.cfg' - name: BUILDBOT_WORKER_PORT value: '9989' - name: BUILDBOT_WEB_URL @@ -59,3 +72,10 @@ spec: name: frontend - containerPort: 9989 name: worker + volumeMounts: + - name: master-persistent-storage + mountPath: /var/lib/buildbot/builds + volumes: + - name: master-persistent-storage + persistentVolumeClaim: + claimName: master-pv-claim
postgres.yaml:
--- a/blogpost/volumes-postgres.yaml +++ b/blogpost/volumes-postgres.yaml @@ -13,6 +13,19 @@ spec: tier: postgres clusterIP: None --- +apiVersion: v1 +kind: PersistentVolumeClaim +metadata: + name: postgres-pv-claim + labels: + app: buildbot +spec: + accessModes: + - ReadWriteOnce + resources: + requests: + storage: 5Gi +--- apiVersion: extensions/v1beta1 kind: Deployment metadata: @@ -45,3 +58,10 @@ spec: ports: - containerPort: 5432 name: postgres + volumeMounts: + - name: postgres-persistent-storage + mountPath: /var/lib/postgresql + volumes: + - name: postgres-persistent-storage + persistentVolumeClaim: + claimName: postgres-pv-claim
worker.yaml:
--- a/blogpost/volumes-worker.yaml +++ b/blogpost/volumes-worker.yaml @@ -13,6 +13,19 @@ spec: tier: worker clusterIP: None --- +apiVersion: v1 +kind: PersistentVolumeClaim +metadata: + name: worker-pv-claim + labels: + app: buidlbot +spec: + accessModes: + - ReadWriteOnce + resources: + requests: + storage: 5Gi +--- apiVersion: extensions/v1beta1 kind: Deployment metadata: @@ -45,3 +58,10 @@ spec: ports: - containerPort: 9989 name: worker + volumeMounts: + - name: worker-persistent-storage + mountPath: /buildbot/builds + volumes: + - name: worker-persistent-storage + persistentVolumeClaim: + claimName: worker-pv-claim
And of lastly we edit the Buildbot master.cfg to use our custom paths for storing and carrying out builds:
diff --git a/blogpost/volumes-master.cfg b/blogpost/volumes-master.cfg index 06ad65b..36212ea 100644 --- a/blogpost/volumes-master.cfg +++ b/blogpost/volumes-master.cfg @@ -78,7 +78,9 @@ c['builders'] = [] c['builders'].append( util.BuilderConfig(name="runtests", workernames=["example-worker"], - factory=factory)) + factory=factory, + builddir='builds', + workerbuilddir='builds')) ####### STATUS TARGETS
This is just an edited version of the original master.cfg you can find in the original Buildbot docker-compose example repository.
So this should just work, right? We request a volume of a given size, the volume exists and is the correct size, badda bing badda boom, do the thing like this:
$ kubectl delete service,deployment,pods --all service "master" deleted service "postgres" deleted service "worker" deleted service "kubernetes" deleted deployment "master" deleted deployment "postgres" deleted deployment "worker" deleted $ kubectl create -f volumes.yaml persistentvolume "local-pv-1" created persistentvolume "local-pv-2" created persistentvolume "local-pv-3" created $ kubectl create -f postgres.yaml service "postgres" created persistentvolumeclaim "postgres-pv-claim" created deployment "postgres" created $ kubectl create -f master.yaml service "master" created persistentvolumeclaim "master-pv-claim" created deployment "master" created $ kubectl create -f worker.yaml service "-worker" created persistentvolumeclaim "worker-pv-claim" created deployment "worker" created $ kubectl get pods -l tier=master NAME READY STATUS RESTARTS AGE master-3176013930-gvy2i 1/1 Running 0 1m $ kubectl port-forward master-3176013930-gvy2i 8080 Forwarding from 127.0.0.1:8080 -> 8080 Forwarding from [::1]:8080 -> 8080
That kinda works, but it kept getting weird arbitrary errors which looked suspicious.

Since the only thing that had really changed was the volumes I figured I might as well login to the host and investigate.
$ minikube ssh docker@minikube:~$ ls -alh /data/ total 20 drwxr-xr-x 5 root root 4.0K Dec 11 02:21 ./ drwxr-xr-x 6 root root 4.0K Dec 11 01:48 ../ drwxr-xr-x 2 root root 4.0K Dec 11 02:20 pv-1/ drwxr-xr-x 2 root root 4.0K Dec 11 02:33 pv-2/ drwxr-xr-x 3 root root 4.0K Dec 11 02:33 pv-3/
Ahah! That's the problem, root owns everything but the builds are run by the buildbot user (uid: 1000) /me shakes fist at permissions errors. The last first place you think to look.
So is there any way to change the permissions of a volume as you claim it (i.e., in volumes.yaml)? We can both go through this journey together or I can share with you a quote from my coworker Barak Michener, the BAMF that works on Torus.
Barak Micheneryeah, hostPath is completely hands-off from k8s perspectiveso you just chmod the underlying dirto whatever uid you're using inside the pod
Turns out the problem was with my type of storage in volumes.yaml. As of yet there is no type-agnostic way to assign permissions for mounted volumes. Storage, why you gotta be like that?
So after digging around and asking Barak I finally concluded that I had to had to login to my host and set the correct permissions on the directories being reserved. Here's how you do that on Minikube:
$ minikube ssh docker@minikube$ sudo chown -R 1000:1000 /data/pv*
In this case we could just chown the one volume that's going to be used by the worker pod, since the other ones run their services as root, but much like Debra from accounting, root doesn't give a fuck. Might as well.
So if we try the build again with the correct permissions, what happens?

Huzah
At last we have what I suspect will be the hardest part of the project: autoscaling. Here's what we want in a perfect world:
This task is actually a pretty tough cookie to crack. We want enough workers to each deal with 1/N requests in a queue of N builds, essentially scaling the building service to deal with usage spikes. It sounds straight forward enough, but how do we test it?
For this we need to add a few projects to our instance of Buildbot, each of which will have a hefty workload. To do this we need to host a Buildbot master.cfg config file at some public location and refer to this in the master.yaml config file. I used the GitHub repo that accompanies this blogpost [accompanying-repo], but you could use GitHub Gists or a pastebin; just make sure you're referring to the raw file or a .tar.gz with the master.cfg file at the base of the tarball.
So let's pull a project out of a hat that takes a while to build, how about... Cargo. Any objections? Great, let's roll.
To get started we'll need a custom worker container can build Cargo. A small adventure later and we have this Dockerfile which has all of the dependencies to build what we want:
FROM buildbot/buildbot-worker:master RUN curl https://sh.rustup.rs -sSf | sh -s -- -y --default-toolchain nightly RUN echo 'PATH=$PATH:$HOME/.cargo/bin' >> $HOME/.bashrc USER root RUN apt update -y RUN apt install -y cmake pkg-config USER buildbot
I set this to auto-build on quay.io, hosted at the docker-pull url quay.io/elijahcaine/buidlbot-rust-worker.
Now that we have a capable worker container, we need to create an arbitrary workload. To do that we'll use this Buildbot master.cfg:
diff --git a/blogpost/robust-master.cfg b/blogpost/robust-master.cfg index 06ad65b..892188b 100644 --- a/blogpost/robust-master.cfg +++ b/blogpost/robust-master.cfg @@ -18,7 +18,7 @@ c = BuildmasterConfig = {} # a Worker object, specifying a unique worker name and password. The same # worker name and password must be configured on the worker. -c['workers'] = [worker.Worker("example-worker", 'pass')] +c['workers'] = [worker.Worker("rust-worker", 'pass')] if 'BUILDBOT_MQ_URL' in os.environ: c['mq'] = { @@ -43,7 +43,7 @@ c['protocols'] = {'pb': {'port': os.environ.get("BUILDBOT_WORKER_PORT", 9989)}} c['change_source'] = [] c['change_source'].append(changes.GitPoller( - 'git://github.com/buildbot/pyflakes.git', + 'git://github.com/rust-lang/cargo.git', workdir='gitpoller-workdir', branch='master', pollinterval=300)) @@ -57,10 +57,10 @@ c['schedulers'].append(schedulers.SingleBranchScheduler( name="all", change_filter=util.ChangeFilter(branch='master'), treeStableTimer=None, - builderNames=["runtests"])) + builderNames=["cargo1-runtests", "cargo2-runtests", "cargo3-runtests"])) c['schedulers'].append(schedulers.ForceScheduler( name="force", - builderNames=["runtests"])) + builderNames=["cargo1-runtests", "cargo2-runtests", "cargo3-runtests"])) ####### BUILDERS @@ -68,17 +68,30 @@ c['schedulers'].append(schedulers.ForceScheduler( # what steps, and which workers can execute them. Note that any particular build will # only take place on one worker. -factory = util.BuildFactory() -# check out the source -factory.addStep(steps.Git(repourl='http://github.com/buildbot/pyflakes.git', mode='incremental')) -# run the tests (note that this will require that 'trial' is installed) -factory.addStep(steps.ShellCommand(command=["trial", "pyflakes"])) +f = {} +f['cargo'] = util.BuildFactory() +f['cargo'].addStep(steps.Git(repourl='git://github.com/rust-lang/cargo.git', mode='full', method='fresh')) +f['cargo'].addStep(steps.ShellCommand(command=["/home/buildbot/.cargo/bin/cargo", "build", "--release"])) c['builders'] = [] c['builders'].append( - util.BuilderConfig(name="runtests", - workernames=["example-worker"], - factory=factory)) + util.BuilderConfig(name="cargo1-runtests", + workernames=["rust-worker"], + factory=f['cargo'], + builddir='builds/cargo1', + workerbuilddir='builds/cargo1')) +c['builders'].append( + util.BuilderConfig(name="cargo2-runtests", + workernames=["rust-worker"], + factory=f['cargo'], + builddir='builds/cargo2', + workerbuilddir='builds/cargo2')) +c['builders'].append( + util.BuilderConfig(name="cargo3-runtests", + workernames=["rust-worker"], + factory=f['cargo'], + builddir='builds/cargo3', + workerbuilddir='builds/cargo3')) ####### STATUS TARGETS @@ -93,8 +106,8 @@ c['status'] = [] # the 'title' string will appear at the top of this buildbot installation's # home pages (linked to the 'titleURL'). -c['title'] = "Pyflakes" -c['titleURL'] = "https://launchpad.net/pyflakes" +c['title'] = "Rusty Stuffy" +c['titleURL'] = "https://www.rust-lang.org/en-US/" # the 'buildbotURL' string should point to the location where the buildbot's # internal web server is visible. This typically uses the port number set in
And deploy it with this master.yaml:
diff --git a/blogpost/robust-master.yaml b/blogpost/robust-master.yaml index c7479e3..f75b4d6 100644 --- a/blogpost/robust-master.yaml +++ b/blogpost/robust-master.yaml @@ -50,7 +50,7 @@ spec: - name: BUILDBOT_CONFIG_DIR value: config - name: BUILDBOT_CONFIG_URL - value: 'https://raw.githubusercontent.com/ElijahCaine/buildbot-on-kubernetes/master/simple/master.cfg' + value: 'https://raw.githubusercontent.com/ElijahCaine/buildbot-on-kubernetes/master/robust/master.cfg' - name: BUILDBOT_WORKER_PORT value: '9989' - name: BUILDBOT_WEB_URL
When we look at our setup in Buildbot it looks like this:
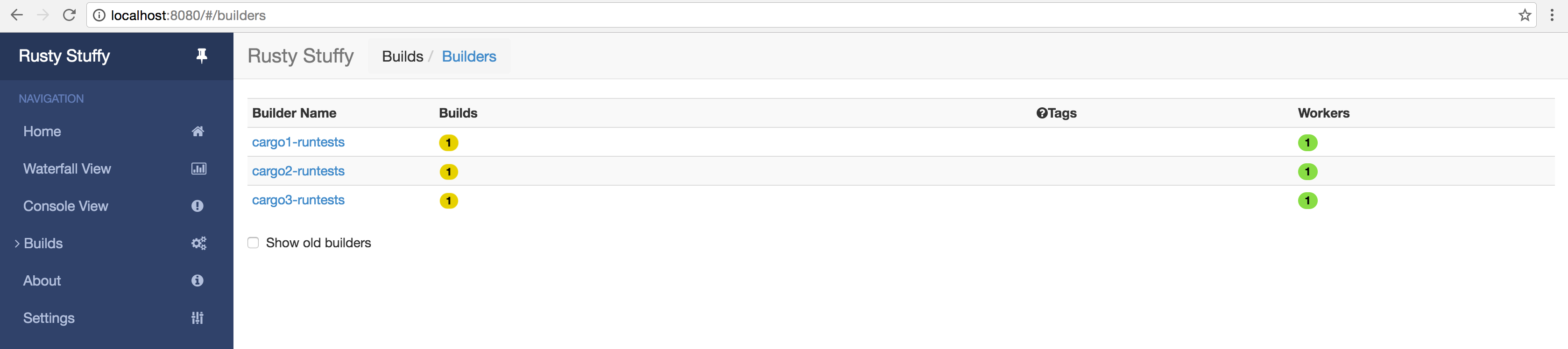
When each build is run it completely wipes away the old git clone and starts from scratch, which is suuuper wasteful, but exactly what we want here. The purpose of this test is to create a heavy workload for our nodes to perform, and with this each build will definitely be heavy.
Now to start scaling that build. In a perfect world we'd get a request, that would start hogging our resources, and K8s would spin up a new worker instance to handle the next build in the queue. Based on the output of kubectl --help it looks like kubectl autoscale deployment worker is the command we want... so let's do that:
$ kubectl autoscale deployment worker --max=5 --min=1 --cpu-percent=50
deployment "worker" autoscaled
$ kubectl describe hpa
Name: worker
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 09 Dec 2016 11:13:15 -0800
Reference: Deployment/worker
Target CPU utilization: 50%
Current CPU utilization: <unset>
Min replicas: 1
Max replicas: 5
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 11s 6 {horizontal-pod-autoscaler } Warning FailedGetMetrics failed to get CPU consumption and request: failed to get pods metrics: the server could not find the requested resource (get services http:heapster:)
37s 11s 6 {horizontal-pod-autoscaler } Warning FailedComputeReplicas failed to get CPU utilization: failed to get CPU consumption and request: failed to get pods metrics: the server could not find the requested resource (get services http:heapster:)
Hmm... that output looks like things aren't working. Let's look around the internet and see if we find anything useful. I'll go East, you go West, and we'll meet back here in 20.
Great, what did you find? Me? Oh I found a bunch of Github issues [hpa-gh] and Stack Overflow posts [hpa-so]; lot of people mentioned this Heapster thing. The Heapster GitHub page says it does Compute Resource Usage Analysis and Monitoring of Container Clusters, which sounds like what we want. I also found the K8s Autoscaling docs that point to a K8s Autoscaling Tutorial. That sounds super useful and confirms the suspicion that Heapster is useful. TLDR things are pointing toward setting up Heapster.
As it turns out there is a Heapster addon for Minikube [heapster-release], so let's get that setup.
$ minikube addons enable heapster heapster was successfully enabled $ minikube addons open heapster Opening kubernetes service kube-system/monitoring-grafana in default browser...
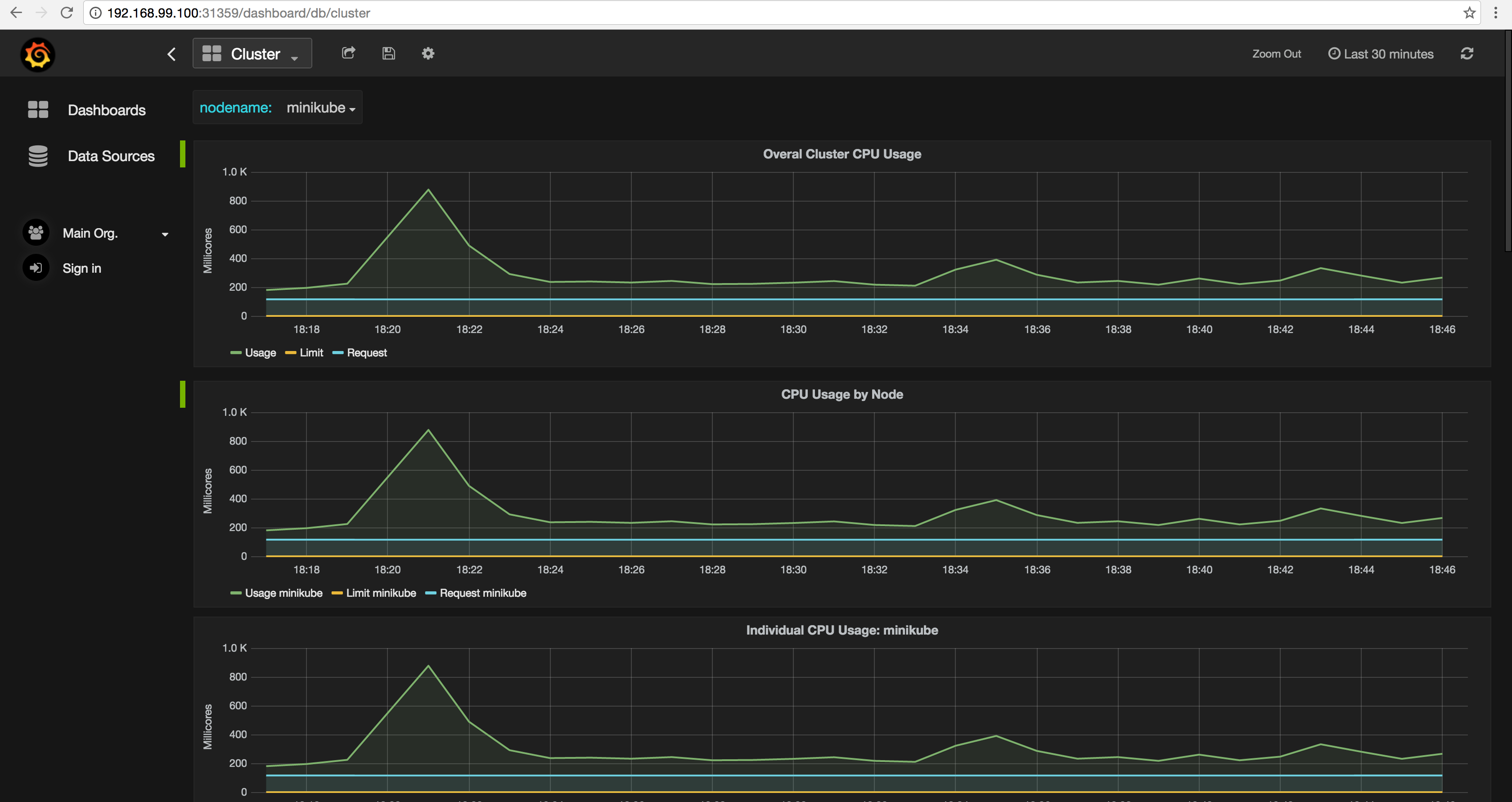
Neato!
So now we've got Heapster running, what's next?
Well the tutorial runs this line:
$ kubectl run php-apache --image=gcr.io/google_containers/hpa-example --requests=cpu=200m --expose --port=80
Which we can appropriate to get some YAML to shove in our worker.yaml to get a good template for our Buildbot worker Deployment.
$ kubectl run test --image=busybox --requests=cpu=200m -o yaml
apiVersion: extensions/v1beta1
...
spec:
...
template:
...
spec:
containers:
- args:
...
resources:
requests:
cpu: 200m
...
So I added that section to worker.yaml...
diff --git a/blogpost/robust-worker.yaml b/blogpost/robust-worker.yaml index e57db12..de52320 100644 --- a/blogpost/robust-worker.yaml +++ b/blogpost/robust-worker.yaml @@ -42,15 +42,18 @@ spec: tier: worker spec: containers: - - image: "buildbot/buildbot-worker:master" + - image: "quay.io/elijahcaine/buildbot-rust-worker:master" name: worker + resources: + requests: + cpu: 200m env: - name: BUILDMASTER value: master - name: BUILDMASTER_PORT value: '9989' - name: WORKERNAME - value: example-worker + value: rust-worker - name: WORKERPASS value: pass - name: WORKER_ENVIRONMENT_BLACKLIST
... and ran kubectl replace -f worker.yaml, but did it work? Well, if you're impatient like me you'll keep refreshing, it won't look like it's working, and then you'll pull your hair out. If that happens to you, just wait. Wait like... a minute. Just get some tea, stare out the window for a second, then see if it worked or not.
$ kubectl get hpa worker NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE worker Deployment/worker 50% 0% 1 5 2m
There. That looks good. Let's throw some work at it!
A few builds:
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE worker Deployment/worker 50% 536% 1 5 6m
Great! Let's check up on Buildbot:

Ruh-roh that's not good...
Let's dig in a bit.
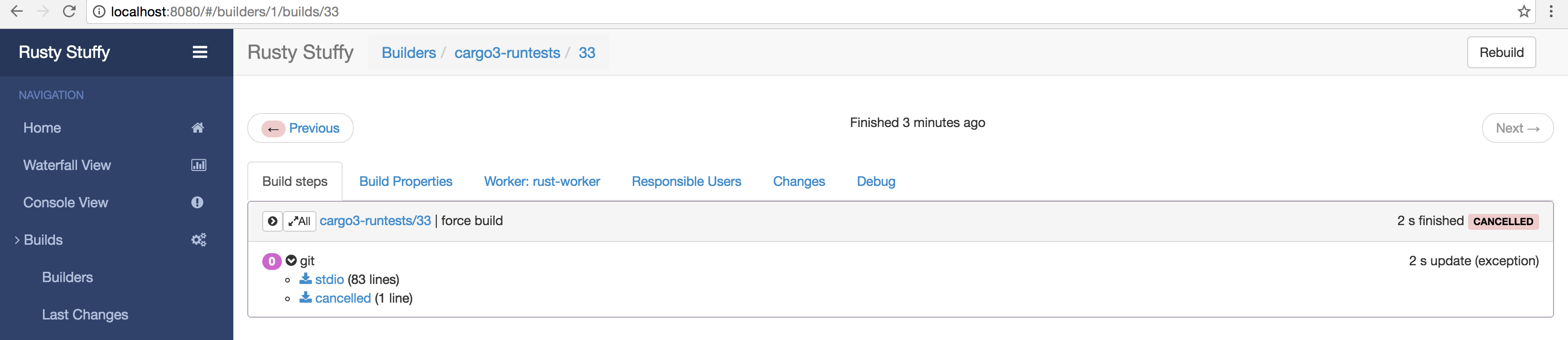
That's not good...
[... end of git pull ...] 75 security_updates_as_of=2016-10-07 76 using PTY: False 77 Cloning into '.'... 78 79 command interrupted, attempting to kill 80 process killed by signal 15 81 program finished with exit code -1 82 elapsedTime=2.051445
[... entirety of 'cancelled' logs ...] 0 no reason
Well, it looks like that plan didn't work.
I did a bit more digging and I can say with certainty that the approach I took to scaling the workload did not work. I can't say why for sure, and I definitely can't say how to fix it, but honestly... it's late. I'm tired and right now I'm okay with throwing in the towel for now. Maybe we'll solve this in a Part 2.
First: This blogpost has a repo associated with it: https://github.com/elijahcaine/buildbot-on-kubernetes.
Please check that out, see what it has to offer, and make issues/pull requests. Right now it's just a copy of the configs used in this project and a little bit of documentation.
Happy hacking!
I'm terrible at endings so I'm just gonna braindump some stuff here and let you, the beautiful and charming reader, find your own closure from all of this.
That's right, I didn't do what I set out to achieve. Is that a bad thing? Of course not! To quote the great Jake the Dog:

Sure we didn't get the perfect BuildBot+K8s but we learned a ton and got really close!
So what are some things we learned that we should probably write down? This is a pretty open question and if you followed along you'll probably get a drastically different list than I have. Here's the big things I feel like I'm walking away with:
I'm sure there's a ton more I've internalized and can't recall. I tried to take thorough notes during this entire experience to capture the failures as well as the successes, which is a harder skill than I expected.
Beyond searching for specific answers these are honestly the websites I kept going back to throughout this project.
As far as Buildbot-specific stuff I honestly just used the official Buildbot docs which were more than enough.
I'm sure I'll be posting more about K8s going forward. It is a very useful tool because of/despite it's complexities. As I use it I'll post more about it.
If you have any feedback on this post feel free to get in contact with me @PastyWhiteNoise on Twitter, pop on irc.freenode.net [irc], you can make an issue on this website's Github Repository, and of course I can be reached by Carrier Pigeon..
| [docs-should] | My job, at least a big part of it, is writing documentation. Docs are a notable part of my identify, and I have a belief in the power of good documentation, but at the end of the day they are just a means to an end. In a perfect world docs wouldn't need to exist, so all docs should be enough to get whoever's readin them to the point where they can do cool shit on their own. Just like a great cinematographer is so good you don't notice the camera in a movie, great docs should be so good you don't notice how good they are. So that's why I like doing cool shit over reading about it. It's also fun to play with toys! Even if those toys are software. |
| [theory-vs-practice] | If you read that and thought "You know what they say about theory versus practice!" then yes -- but you're getting ahead of me. |
| [same-app-note] | It wasn't painfully obvious to me so it's worth elaborating that for K8s services to communicate with one-another they need to be part of the same app. In the example the postgres, worker, and master containers are all part of the same buildbot app. It's not a terribly well documented key piece of information so it seemed worth mentioning. |
| [hpa-gh] |
| [hpa-so] |
| [heapster-release] | Authors Note:
The heapster addon was added to Minikube during the writing of this post.
How convenient!
|
| [accompanying-repo] | https://github.com/ElijahCaine/buildbot-on-kubernetes |
| [irc] | I usually hang out in the #osu-lug channel. They're cool people, you should hang out with us! |
| [why] | Might as well clarify why we want persistent storage and auto-scaling since these are usually desired features in an orchestrator but nobody explains why they're desireable.
|
| [GIFEE] | Google Infrastructure for Everyone Else |
| [storge] | But neither is storage in general so who can blame 'em? |